Oracle Datenbank 12c Release 2 unterstützt parallel NFS (pnfs)
Oracle hat die direkte NFS Implementierung (dNFS) – das bedeutet, dass die Datenbank Prozesse eigene NFS Verbindungen erzeugen und nicht auf das OS NFS angewiesen sind – mit Oracle 11g Release 1 eingeführt. Zu diesem Zeitpunkt war lediglich NFS v3 unterstützt.
Die Unterstützung für NFS v4.0 und NFS v4.1 (ohne pNFS) ist mit Oracle 12c Release 1 hinzugekommen. Die Unterstützung von Parallel NFS folgt nun mit Oracle 12c Release 2.
Was bedeutet direct NFS genau und welche Vorteile bietet es?
Wenn man von NFS spricht, versteht man darunter ein Protokoll, mit dem man Verzeichnisse auf anderen Systemen lokal anbinden kann. Dazu braucht man einerseits NFS Server, um ein Verzeichnis freigeben zu können, und andererseits NFS Clients um ein freigegebenes Verzeichnis lokal einzubinden.
Möchte jetzt ein Prozess auf dieses NFS Share zugreifen, wird der Zugriff an den NFS Client übergeben, der sich um die Kommunikation mit dem NFS Server kümmert. Dieser Zwischenschritt (Kommunikation mit dem NFS Client und dessen Verarbeitung) bedeutet in weiterer Folge, dass
-
die Daten mindestens einmal im Memory kopiert werden müssen,
-
es zu einem oder mehreren Context Switches (wechseln von einem Prozess zu einem anderen) kommt
-
und natürlich CPU Zeit konsumiert wird.
Die NFS Clients wurden für den Zugriff auf Dateien, aber nicht für zufällige Zugriffe, die eine Datenbank benötigt, optimiert.
Bei Oracle direct NFS verbindet (mountet) sich jeder Oracle Prozess jene NFS Shares, auf die dieser zugreifen muss, selbst. Dadurch wird der lokale NFS Client umgangen – er wird nicht mehr benötigt, muss aber als eine Art „Fallback“ trotzdem existieren und konfiguriert sein.
Der wesentliche Vorteil ist, dass jeder Oracle Prozess eine eigene „I/O Queue“ hat, sprich sich um seine eigenen I/Os kümmert. Im Fall von NFS Clients werden alle Zugriffe über eine (oder wenige) I/O Queues verwaltet – was dazu führt, dass ein I/O nicht sofort an den NFS Server geschickt wird, sondern zuerst lokal im NFS Client warten muss, bis er verarbeitet werden kann.
Wir haben schon bei vielen Kunden POCs unter dem Titel „Oracle dNFS versus OS NFS“ gemacht und typischerweise eine Durchsatzsteigerung von 50 – 100% nachweisen können, wobei gleichzeitig die CPU Belastung deutlich reduziert wurde.
Ein Beispiel dafür finden Sie auch auf unserer Homepage:
Was ist der Unterschied zwischen NFS v3, NFS v4.0, NFS v4.1 und pNFS?
Der wesentliche Unterschied zwischen NFS v3 und den anderen Versionen liegt in der Architektur. Während NFS v3 sehr simpel gestrickt ist – es existiert schon seit 1995 – fehlen viele Funktionalitäten, die man sich von einem Filesystem eigentlich wünscht. Dies sind beispielsweise:
-
Unterstützung eines einheitlichen Namensbereiches (Namespace)
-
Unterstützung für Migration und Replikation
-
Zusammenfassung mehrere Operationen zu einem Aufruf (compound Operations)
-
Echtes Sperren von Files (File Locking) – NFS v3 nutzt dazu den Network Lock Manager, ab NFS v4 ist es ein integraler Bestandteil von NFS.
Die Version NFS v4.1 erweitert das Protokoll um die Unterstützung von Storage Clustern und enthält auch schon die parallel NFS Funktionalität.
Im Internet findet man sehr viele Benchmarks „NFS v3 versus v4“, bei denen (fast) alle feststellen, dass NFS v4 langsamer ist als NFS v3. Die meisten dieser Benchmarks testen allerdings mit EINEM Client gegen EINEN NFS Server. In diesem Fall wird NFS v4 meistens schlechter abschneiden, da im Protokoll mehr Funktionalität enthalten ist. Wir haben keine Benchmark-Ergebnisse gefunden, die Funktionalitäten wie pNFS, Migration und Replication genutzt hätten.
pNFS Architektur
Bei pNFS wird zwischen den Metadaten – wo liegen welche Shares und wie kann man diese (über mehrere Wege) erreichen – sowie den Data Servern (wo die Shares/Daten liegen) unterschieden. Alle Data Server bieten potentiell die gleichen Daten an.
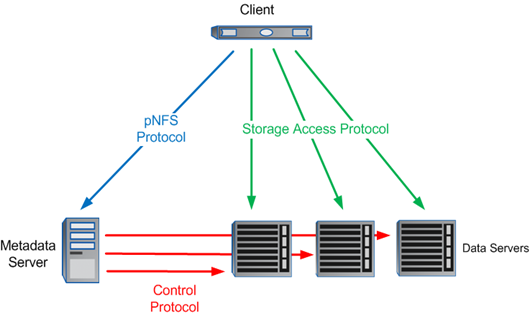
Der Metadaten Server behandelt alle nicht Daten (I/O) Anfragen wie: LOOKUP, GET/SETATTR, ACCESS, REMOVE, RENAME, etc.
Die Daten Server sind ausschließlich für READ und WRITE I/O zuständig.
Je nach Implementierung durch den NFS Storage Hersteller können die Metadaten auch von mehreren Servern angeboten werden – hier ein Beispiel von der NetApp Implementierung.
NFS v4 sieht vor, dass alle Daten in einem gemeinsamen Namespace abgebildet sind. Physisch liegen die Daten aber in Volumes auf einem der Storages. In diesem Beispiel greift der pNFS Client 1 auf /vol1 über die Storage Node D zu (mount). Das gilt aber nur für die Metadaten. Der Zugriff auf die Daten erfolgt dann über jenen Server wo diese Daten physisch liegen – in dem Beispiel auf der Storage Node B.
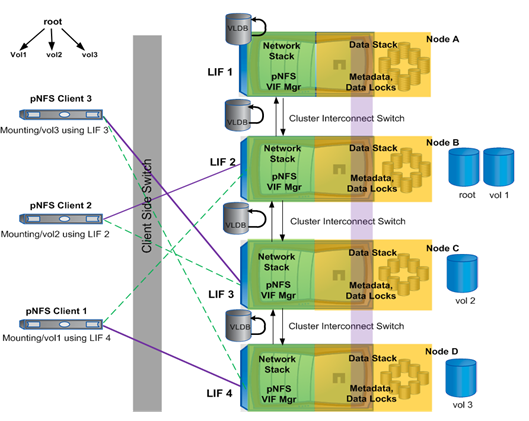
Werden die Daten innerhalb der Storages verschoben, beispielsweise das Volume vol1 von Storage Node B auf Storage Node A, so würde der Client im ersten Augenblick immer noch via Storage Node B zugreifen, die dann Ihrerseits die Daten über den Cluster Interconnect auf die Storage Node A zugreifen müsste um die Daten zu liefern – das ist klarerweise ein Overhead und dauert länger. Daher sieht pNFS vor, dass Client 1 informiert wird, dass die Daten nun über eine andere IP Adresse zu beziehen sind und der Client 1 greift dann direkt auf die Storage Node A zu.
Quellen:
Versuchsaufbau Oracle 12cR2 mit dNFS mit und ohne pNFS
-
Oracle VM Server mit einer VM mit Oracle 12cR2.
-
NetApp FAS 3170 Cluster bestehend aus zwei Storage Heads mit jeweils 51 Stück 300GB Harddisks
-
Einem VServer und zwei LIFs (IP Adressen – eine pro Storage Head)
-
Jumbo Frames (MTU=9000) konfiguriert
Dieser Aufbau (ältere Hardware, virtualisiert, ...) ermöglicht keine Aussage über die absoluten Performance Werte aktueller Intel Server und NetApp Storages – diese sind deutlich schneller! Wir haben schon vor über 5 Jahren POCs mit über 140.000 IOPS und über 1.000 MBPS gemacht. Die Hardware ist aber ausreichend um Performanceunterschiede der verschiedenen NFS Versionen festzustellen.
NetApp Storage Konfiguration
Die beiden FAS3170 bilden einen Cluster aus zwei Knoten (fas3170a, fas3170b). Auf den Storage Knoten gibt es 10GBit LAN Interfaces auf denen jeweils ein LIF (virtuelles Interface) des vServers vsdb122b konfiguriert ist.

Obwohl es zwei DATA Volumns gibt, liegen die Datenbankfiles nur auf dem Volumns DATA1. Die Volumes sind jeweils auf den Disken eines der Storage Knoten angelegt:
-
DATA1 liegt auf FAS3170a - nur DATA1 wird für Datenbankfiles genutzt
-
DATA2 liegt auf FAS3170b
Bei den verschiedenen Tests wird das DATA1 Volume von einem Storage Knoten auf den anderen verschoben.
Oracle 12cR2 VM Konfiguration
Die Oracle 12c Release 2 Datenbank läuft auf einem Oracle VM Server mit Dual Intel Xeon X5450 (3GHz) und in Summe 8 Cores. Die Storageanbindung erfolgt über 10GBit Netzwerkkarten mit der IP Adresse 10.146.2.61. Die VM selbst läuft unter OEL 7.3 und darf 4 Cores nutzen.
Die 8GB große Datenbank liegt lediglich im NetApp Volume DATA1 und dieses wird mittels NFS auf /u01/app/oracle/oradata/DB122B/data1/ gemountet. Damit ist diese klein genug um in das Cache der FAS3170 Storage Knoten zu passen.
select name from v$datafile;
NAME
------------------------------------------------------------
/u01/app/oracle/oradata/DB122B/data1/system01.dbf
/u01/app/oracle/oradata/DB122B/data1/sysaux01.dbf
/u01/app/oracle/oradata/DB122B/data1/undotbs01.dbf
/u01/app/oracle/oradata/DB122B/data1/pdbseed/system01.dbf
/u01/app/oracle/oradata/DB122B/data1/pdbseed/sysaux01.dbf
/u01/app/oracle/oradata/DB122B/data1/users01.dbf
/u01/app/oracle/oradata/DB122B/data1/pdbseed/undotbs01.dbf
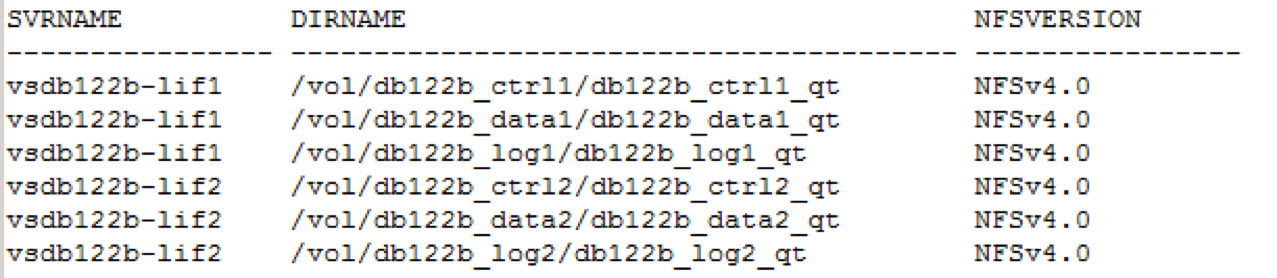
Die Oracle Datenbank wurde zur Nutzung von dNFS konfiguriert - siehe auch: Oracle dNFS richtig konfigurieren. Die erfolgreiche Konfiguration von dNFS kann man beispielsweise in v$dnfs_servers verifizieren:
select SVRNAME, DIRNAME from V$DNFS_SERVERS;
SVRNAME DIRNAME NFSVERSION
------------- ---------------------------------- ---------
vsdb122b-lif1 /vol/db122b_ctrl1/db122b_ctrl1_qt NFSv3.0
vsdb122b-lif1 /vol/db122b_data1/db122b_data1_qt NFSv3.0
vsdb122b-lif1 /vol/db122b_log1/db122b_log1_qt NFSv3.0
vsdb122b-lif2 /vol/db122b_ctrl2/db122b_ctrl2_qt NFSv3.0
vsdb122b-lif2 /vol/db122b_data2/db122b_data2_qt NFSv3.0
vsdb122b-lif2 /vol/db122b_log2/db122b_log2_qt NFSv3.0
Neben dieser View gibt es noch weitere Views mit Informationen zu dNFS:
-
V$DNFS_CHANNELS … welche NFS Verbindungen die Datenbank nutzt
-
V$DNFS_FILES … welche Files auf dNFS liegen
-
V$DNFS_STATS ... Performance Statistiken pro File
Diese Views werden im Rahmen der Performance Tests für die Performanceanalyse herangezogen.
Die IP Adressen der LIFs sind im /etc/hosts eingetragen, damit es keine Namensauflösungsthemen geben kann:
cat /etc/hosts
10.146.146.61 vsdb122b-lif1.example.com vsdb122b-lif1
10.146.146.161 vsdb122b-lif2.example.com vsdb122b-lif2
Da es mehrere Wege zu den Daten gibt, braucht man eine oranfstab Konfiguration. Diese ist auch nötig um pNFS einzuschalten. Dazu muss man den Parameter nfs_version auf pNFS einstellen – Beispiele für die oranfstab folgen bei den verschiedenen Performance Test.
Referenzen zur Konfiguration von pNFS:
Oracle 12cR2 Database Installation Guide: Creating an oranfstab File for Direct NFS Client
Performance Test – Überblick
Als Performancetest nutzen wir Oracle I/O Calibrate wobei wir für die Anzahl von Disks 100 einsetzen (zwei mal 50) sowie eine maximale Latenz von 20. Mir sind die verschiedenen Gründe, die gegen diesen Test sprechen durchaus bewusst (keine SQL Verarbeitung, kein Schreiben,..). Da es uns bei den Tests aber nur darum geht, den Performanceeinfluss mit und ohne pNFS zu ermitteln, reicht uns ein Test, der lediglich lesend auf die Oracle Datenbankfiles zugreift. Für die CPU Bewertung werden nur die RANDOM I/O Teile des IO Calibrate herangezogen, wobei der IO Calibrate immer zwei Mal hintereinander gelaufen ist, da beim ersten Lauf das Cache potentiell nicht befüllt war.
Die Datenbankgröße ist mit ca. 8GB so gewählt, dass die Datenbank komplett ins Memory der jeweiligen Storage Node passt. Das wurde deswegen so gewählt, weil es um den Performanceunterschied bzw. Performanceoverhead geht – der sich im Microsekundenbereich bewegt – und nicht um die disk io performance, die im ms Bereich liegt.
Zusätzlich ermitteln wir die CPU Auslastung sowohl auf dem Datenbank Server als auch auf den NetApp Storage Knoten. Leider stehen die NetApp Storages nicht exklusive für unsere Tests zur Verfügung, die CPU Auslastung schwankt ohne Tests zwischen 3% und 10% und zwischen 500 und 2000 Netzwerk Paketen. Da unsere Tests eine deutlich höhere Last generieren, sollte trotzdem eine Aussage möglich sein.
Vor jedem Test wir die Oracle Datenbank Instanz restartet um einerseits die möglicherweise geänderten Einstellungen in der oranfstab zu übernehmen und andererseits ein Cleanup er v$dnfs views zu erreichen.
Performance Test #1: NFSv3, Zugriff auf DATA1 auf FAS3170a via LIF auf FAS3170a
In der oranfstab wurde nfs_version nicht spezifiziert, wodurch die Datenbank Instanz den Default von NFSv3 verwendet hat.
select SVRNAME, DIRNAME from V$DNFS_SERVERS;
SVRNAME DIRNAME NFSVERSION
------------- ---------------------------------- ---------
vsdb122b-lif1 /vol/db122b_ctrl1/db122b_ctrl1_qt NFSv3.0
vsdb122b-lif1 /vol/db122b_data1/db122b_data1_qt NFSv3.0
vsdb122b-lif1 /vol/db122b_log1/db122b_log1_qt NFSv3.0
vsdb122b-lif2 /vol/db122b_ctrl2/db122b_ctrl2_qt NFSv3.0
vsdb122b-lif2 /vol/db122b_data2/db122b_data2_qt NFSv3.0
vsdb122b-lif2 /vol/db122b_log2/db122b_log2_qt NFSv3.0
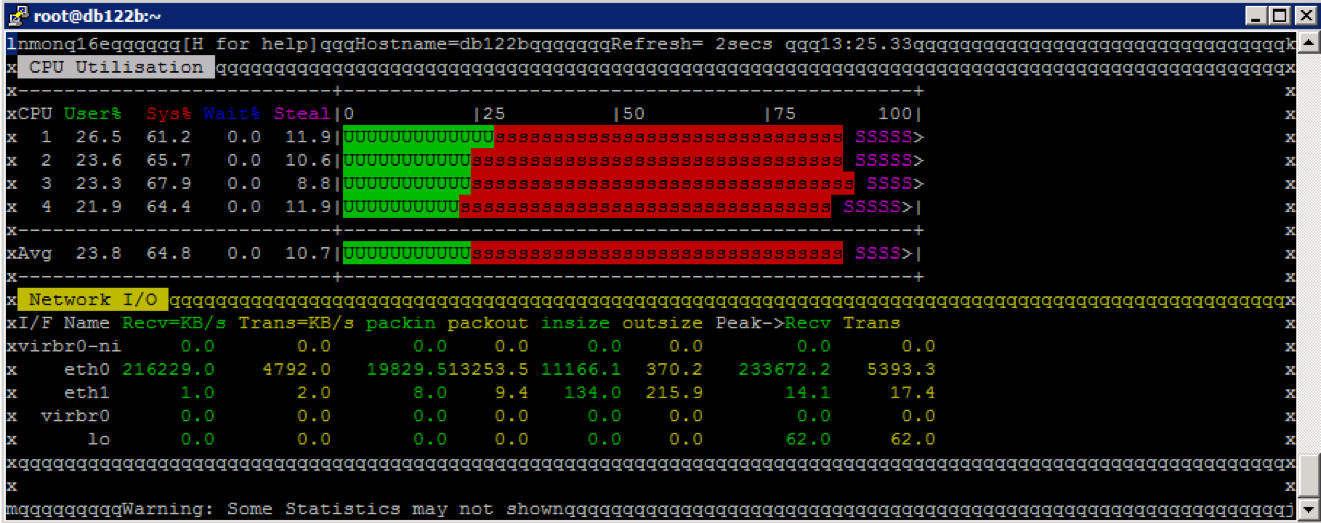
Die CPU Auslastung am Datenbank Server
Die CPU Auslastung via NMON zeigt (10% Steal), dass die VM zu wenig CPU Ressourcen anbietet und als limitierender Faktor zu sehen ist.
CPU Auslastung NetApp Storage
FAS3170a … hier liegt DATA1

Die CPU Auslastung schwankt zwischen 30% und kurzfristig bis zu 55%. Wenn man die typische Basisbelastung abzieht sollte die CPU Belastung durch den Benchmark zwischen 30% und 45% liegen.
Die Cores der Storage sind relativ gleichmäßig ausgelastet.
FAS3170b ... durch Benchmark wie zu erwarten kein zusätzlicher IO.
Oracle File - IO Statistik (v$iostat_file)
Hier liefert Oracle Informationen zu den I/O Requests von IO Calibrate. Da uns speziell die random I/O Latenz interessiert, betrachten wir nur die „small read IOs“.

Die Leselatenz beträgt quer über alle Datenbankfile ca. 355us (also 0.355ms).
Ergebnis des IO Calibrate
IOPS = 27066
Performance Test #2: NFSv3, Zugriff auf DATA1 auf FAS3170b via LIF auf FAS3170a
Das Volume DATA1 wird von den Disks von FAS3170a auf die Disks von FAS3170b verschoben. Der Zugriff erfolgt weiterhin über die IP von FAS3170a. Das verschieben geht online und hat keine Auswirkungen auf die NFS Mounts.
CPU Auslastung am Datenbank Server
Die Auslastung am Datenbank Server ist vergleichbar mit dem ersten Test.
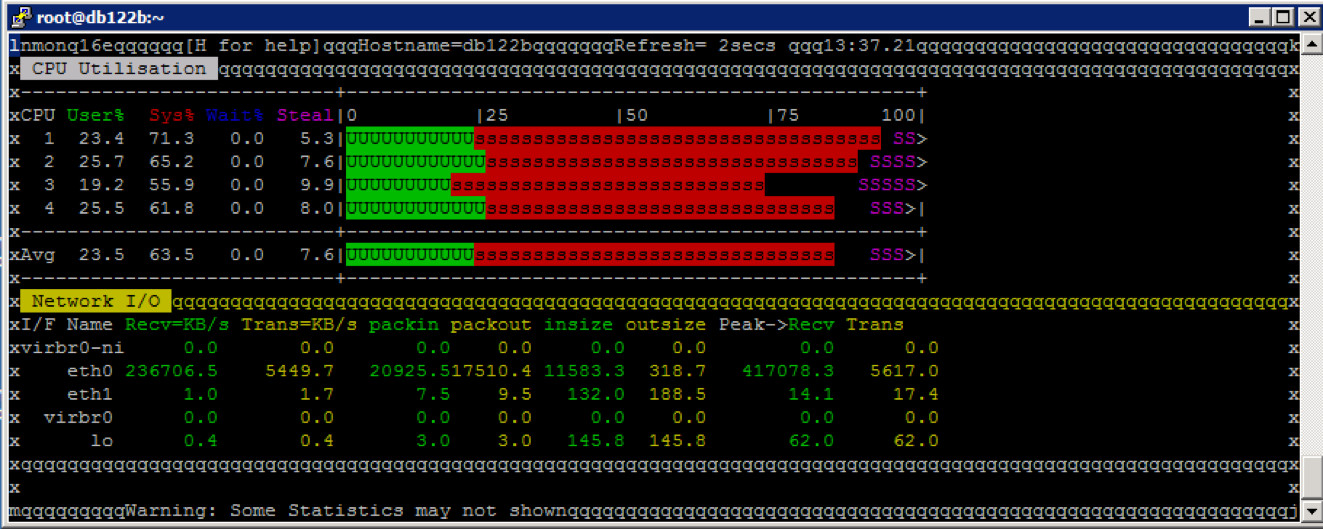
CPU Auslastung der NetApp Storage
Auf der NetApp Storage sieht das Bild jetzt dramatisch anders aus.
FAS3170a ... hier ist die IP Adresse über die zugegriffen wird.

Die CPU Auslastung schwank zwischen 20% und knapp 40% - nur dafür, dass die IO Requests über den Cluster Interconnect hin und wieder zurückgegeben werden.
Wenn man sich die CPU Auslastung im Detail ansieht – der Head hat 4 Cores, sieht man, dass zwei dieser Cores deutlich mehr ausgelastet sind als die anderen beiden.
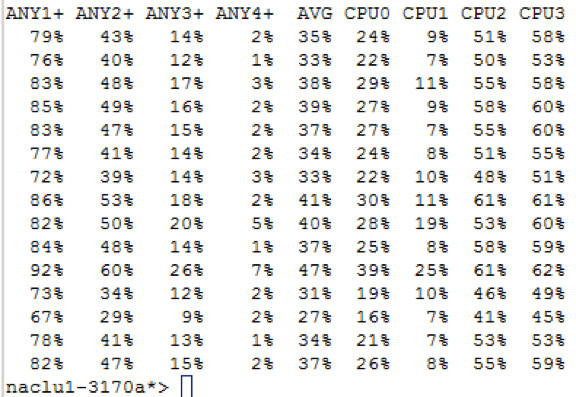
Die CPU Auslastung schwank zwischen 20% und knapp 40% - nur dafür, dass die IO Requests über den Cluster Interconnect hin und wieder zurückgegeben werden.
FAS3170b ... hier liegen die Daten auf den Disken.

Hier sehen wir die Last, die zuvor auf FAS3170a zu sehen war. Die CPU Last schwank zwischen 20% bis zu 50%, wobei Werte unter 30% und über 40% eher als Ausreißer zu sehen sind.
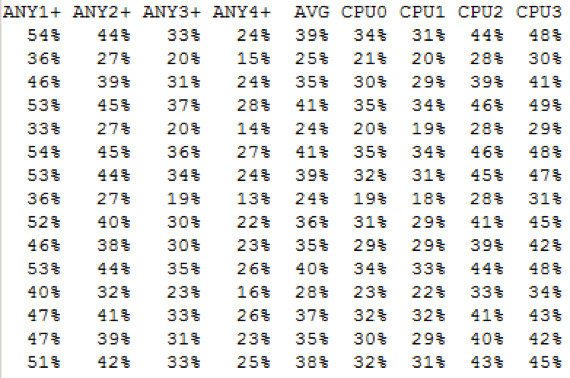
Auf diesem Knoten sind alle CPUs ähnlich stark ausgelastet.
Betrachtet man die I/O Zeiten für Small Reads aus v$iostat_file und errechnet daraus die durchschnittlichen small reads I/O Zeiten bekommt man folgendes Ergebnis:

Ergebnis des IO Calibrate
I/O Ops/sec = 26416
Greift man über eine Netzwerkkarte auf einem Storage Knoten auf Daten zu, die auf dem anderen Storage Knoten liegen, so erzeugt das auf beiden Storage Knoten annähernd die gleiche CPU Belastung – sprich man verdoppelt den CPU Bedarf auf den Storages durch diese Zugriffe über die falsche IP Adresse. Das Ergebnis des I/O Calibrate ist praktisch ident – von der Datenbank aus merkt man keinen Unterschied – die zusätzliche Latenz dadurch, dass der I/O über zwei Storage Heads läuft, liegt somit im Bereich von deutlich unter 0.04ms.
Die interne Messgenauigkeit beim I/O Calibrate liegt bei ganzen ms, da ist die Auswertung über v$iostat_file (mit Microsekunden) deutlich sinnvoller.
Performance Test #3: nur NFSv4, Zugriff auf DATA1 auf FAS3170a via LIF auf FAS3170a
Im dritten Test steigen wir von NFSv3 nun auf NFSv4 um – allerdings noch immer ohne pNFS Funktionalität.
In der oranfstab wird jetzt die nfs_version auf nfsv4 für alle Mounts eingestellt:
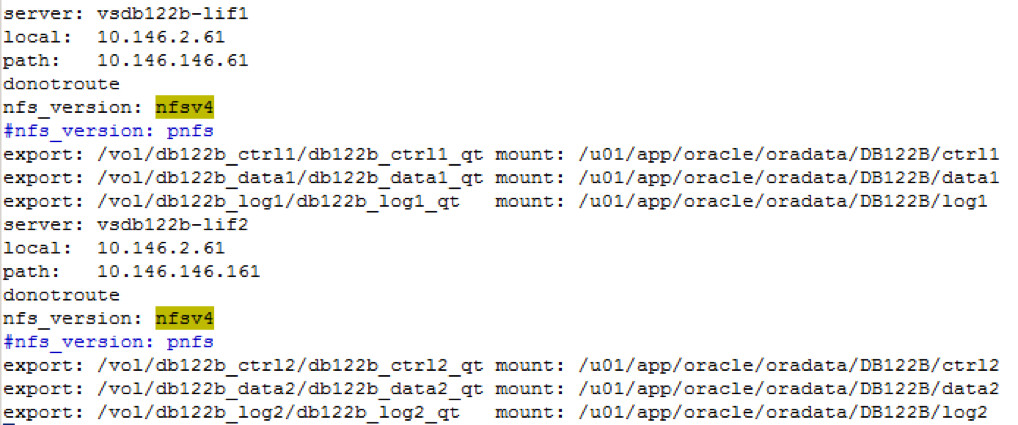
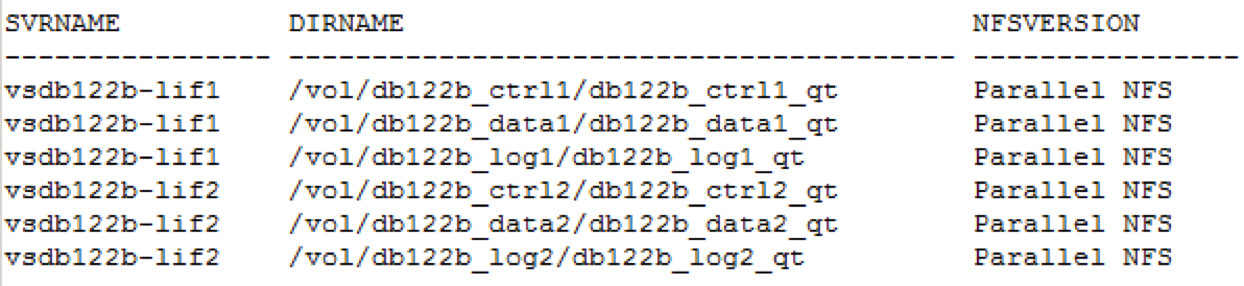
Das wird auch in v$dnfs_servers korrekt wiedergegeben:
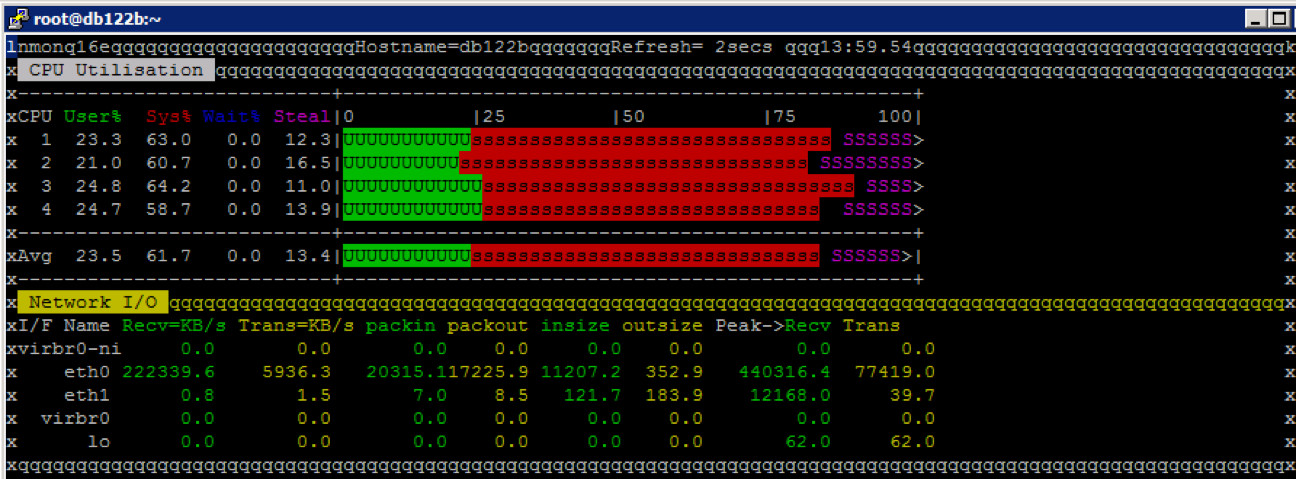
Die CPU Auslastung am Datenbank Server
Die CPU Auslastung am Datenbank Server liegt im gleichen Bereich wie bei NFSv3.
CPU Auslastung der NetApp Storage
Auf den Storages sieht man Unterschiede im Vergleich mit NFSv3 – die Metadata werden offensichtlich von beiden Storage Knoten abgefragt.
FAS3170a

Die CPU Auslastung im Detail
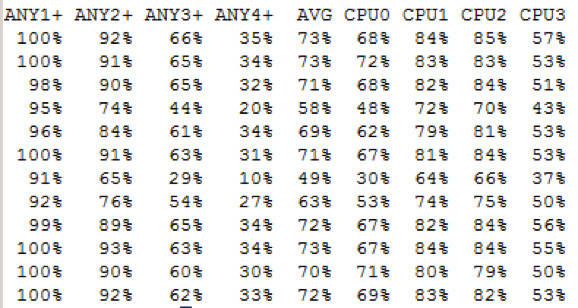
Allgemein ist der CPU Bedarf auf der Storage bei der Verwendung von NFSv4 merklich höher, das liegt an der deutlich höheren Komplexität des Protokolls auf Grund der zusätzlichen Funktionalitäten. Bei unseren schon etwas älteren Storages steigt die CPU Belastung von zuvor zwischen 30% und 45% (NFSv3) auf 50% bis knapp über 70% - somit um ca. 20%.
FAS3170b
Wie zu erwarten ist hier die Belastung sehr gering.

Die CPU Auslastung im Detail
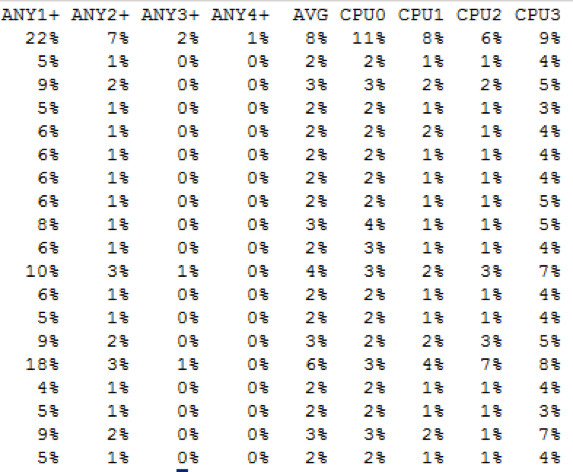
Während bei NFSv3 beim Zugriff über den richtigen Storage Knoten der andere Storage Knoten überhaupt nichts zu tun hatte, sieht man hier eine – zwar geringe – aber messbare Auslastung. Da diese stark schwankt (beim Start vom IO Calibrate lag diese einige Zeit lang bei knapp 10%) und mit der Zeit geringer wurde, dürfte es sich aber nur um einige % handeln, die das Abfragen der Metadaten auf den zweiten Storage Knoten an Last erzeugt.
V$IOSTAT_FILE
Betrachtet man die I/O Zeiten in v$iostat_file, so sieht man, dass diese ebenfalls merklich höher sind als bei der Verwendung von NFSv3.
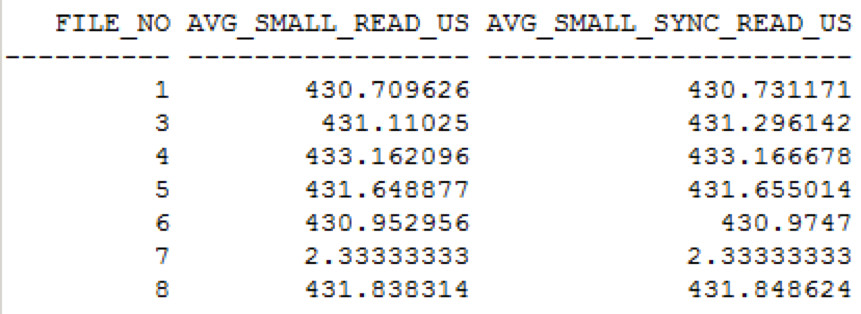
Diese liegen im Bereich von 430us somit um 75us (0.075ms) höher als bei NFSv3.
Ergebnis des IO Calibrates
I/O Ops/sec = 23536
Auch die Ergebnisse vom I/O Calibrate sind – bei den für uns relevanten IOPS – deutlich schlechter und es wird auch eine höhere Latenz angegeben, die wir auf die anfänglichen Metadatazugriffe zurückführen, da diese in v$iostat_file durchschnittlich immer noch unter 0.45ms liegen.
Performance Test #4: NFSv4, Zugriff auf DATA1 auf FAS3170b via LIF auf FAS3170a
Die oranfstab bleibt wie beim vorigen Test. Es werden lediglich die Daten wieder auf die Disken der FAS3170b migriert.
CPU Auslastung am Datenbank Server
Bei der CPU Last und beim Netzwerkdurchsatz am Datenbank Server ist klar zu sehen, dass im Vergleich zu den bisherigen Performance Tests etwas nicht stimmt. Die CPU Auslastung ist deutlich niedriger – was ja positiv wäre, wäre nicht gleichzeitig der I/O Durchsatz massiv schlechter. Das wird sich natürlich in den I/O Calibrate Werten deutlich wiederspiegeln.
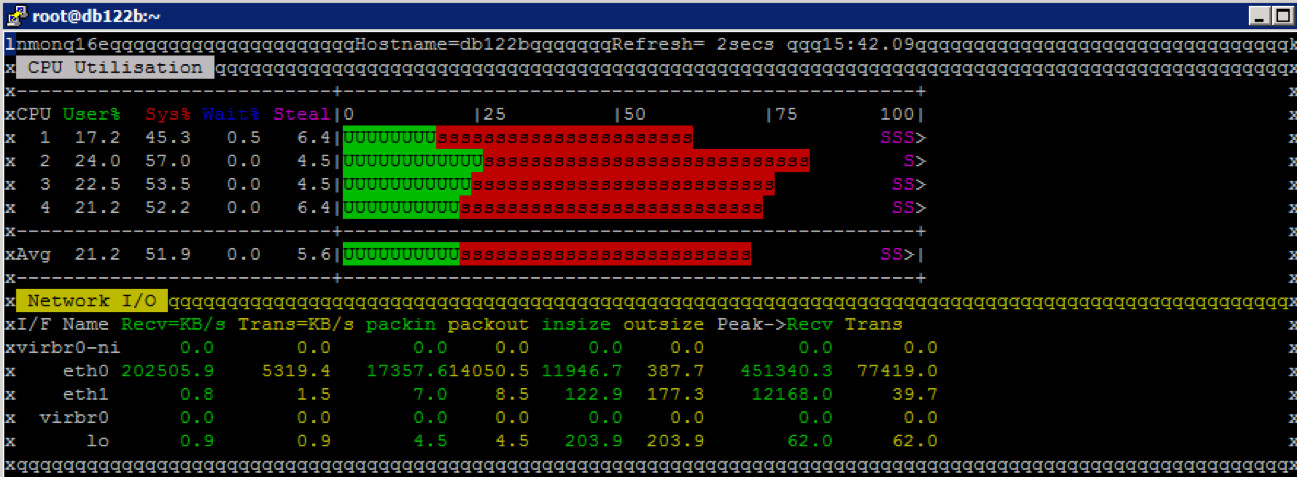
CPU Auslastung der NetApp Storage
FAS3170a
Die CPU Belastung auf dem Knoten der die Kommunikation mit dem Datenbankserver übernimmt ist zwar geringer als beim dem vorigen Test, allerdings werden ja alle I/O Operationen an den anderen Storage Knoten weitergereicht.

Die CPU Auslastung im Detail
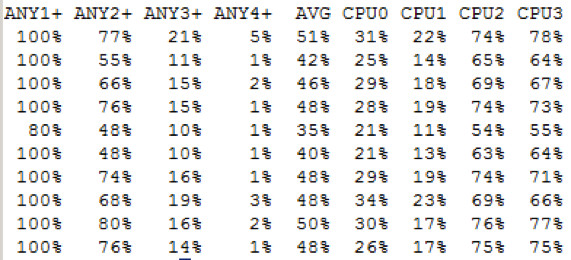
Es sind wieder zwei CPUs stärker ausgelastet, die Belastung pendelt zwischen 40% und knapp über 50% mit Peaks auf über 60%.
FAS3170b – hier befinden sich aktuell die Daten

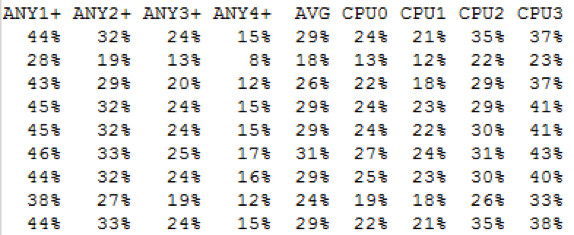
Die CPUs sind alle mehr oder weniger gleichmäßig mit 25 bis 40% ausgelastet.
Was finden wir in v$iostat_file vor?

Wie zu erwarten dauern die I/Os länger – mit durchschnittlich knapp 500us (0.5ms) bedeutet dieser Umweg ca. 70us längere I/O Zeiten. Das wirkt ich natürlich auf die Ergebnisse von I/O Calibrate aus.
IO Calibrate Ergebnis
I/O Ops/sec = 20780
Diese brechen bei den IOPS von über 23.000 IOPS (Test#3) auf weniger wie 21.000 IOPS ein – das sind rund 10%.
Wenn man an dieser Stelle einen Vergleich zwischen NFSv3 und NFSv4 macht (was bei vielen Benchmarks leider gemacht wird), würde das Ergebnis wie folgt aussehen:

-
NFSv4 ist langsamer als NFSv3 – weniger IOPS, höhere I/O Zeiten
-
Der Zugriff über den "falschen" Storage Kopf führt zwar ebenfalls zu geringeren IOPS Zahlen und höheren IO Zeiten, aber das Entscheidende ist die massiv höhere CPU Belastung auf den Storage Knoten - dieses Problem sollte pNFS beheben.
Performance Test #5: pNFS, Zugriff auf DATA1 auf FAS3170a via LIF auf FAS3170a
Im ersten Schritt in der oranfstab auf pNFS umstellen.
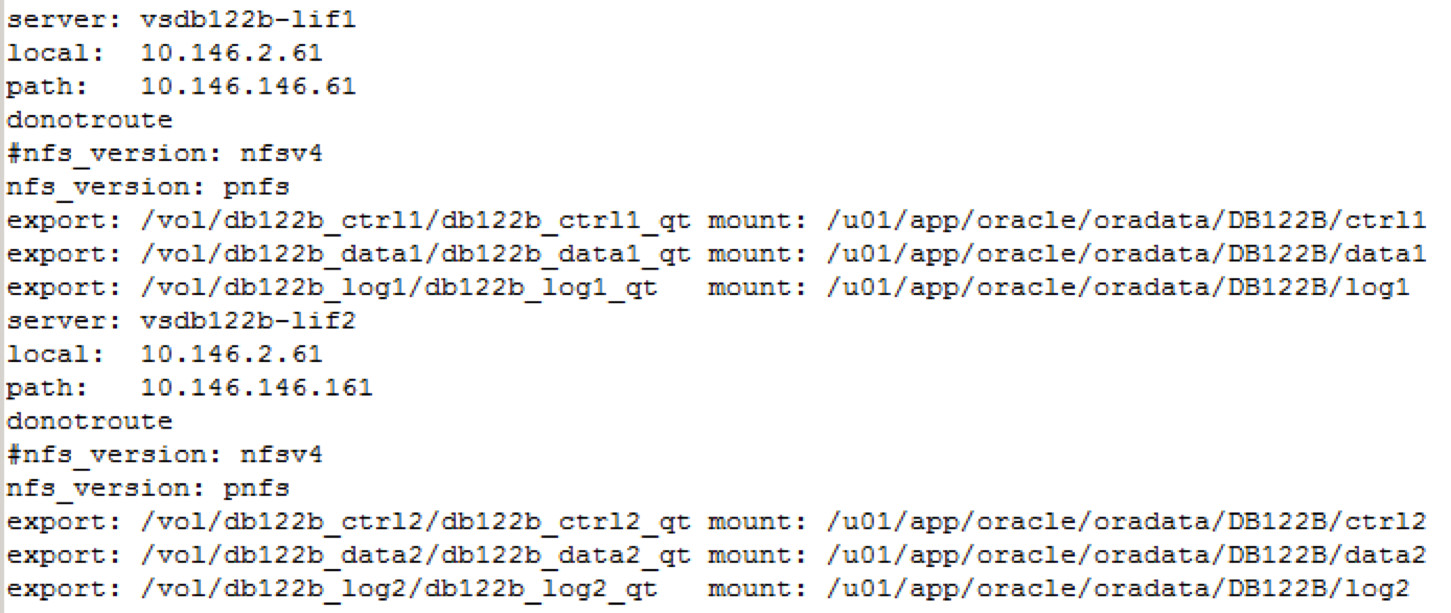
Das wird auch in v$dnfs_servers korrekt wiedergegeben:
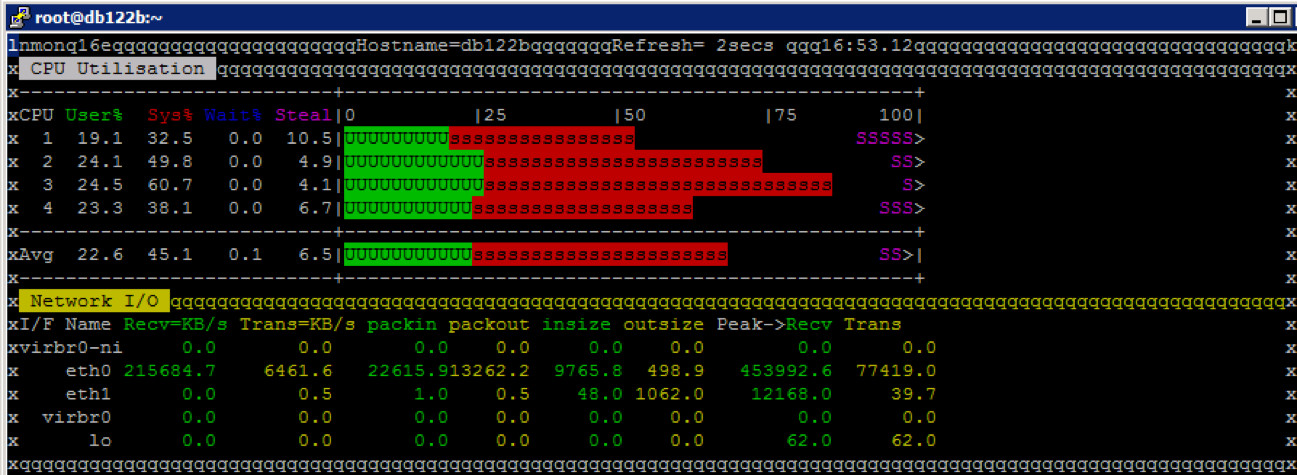
CPU Auslastung am Datenbank Server
Auffällig an der CPU Belastung des Datenbank Servers ist, dass diese niedriger ausfällt als angenommen (unter 70% - etwas niedriger als beim Test davor), aber dabei gleichzeitig der Netzwerkdurchsatz mit dem bei NFSv3 vergleichbar ist!
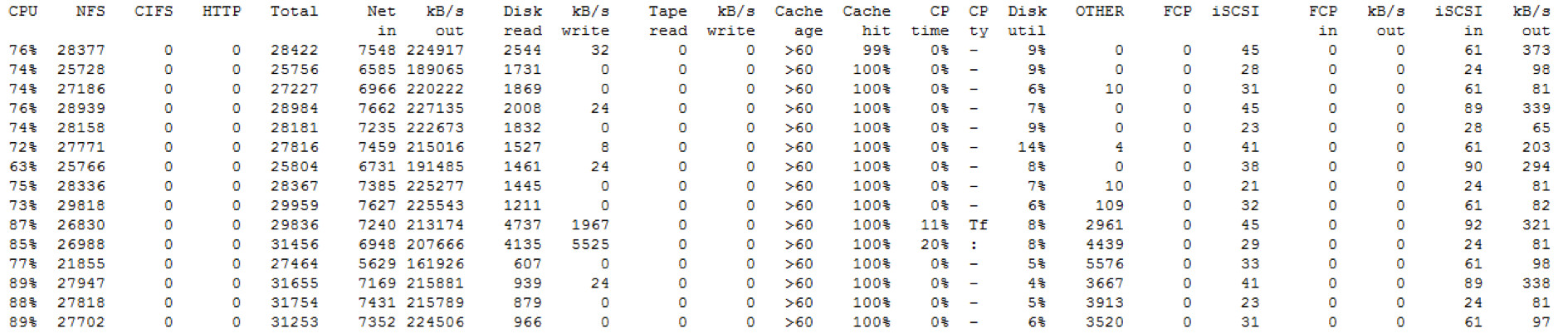
Storage CPU Auslastung
FAS3170a
Auf dem Storage Knoten liegt die durchschnittliche Belastung im Bereich von 60% - 80% mit Peaks auf 90%.
Die CPU Auslastung im Detail
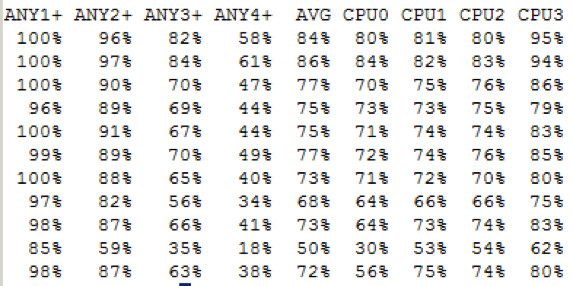
Wobei die Last auf alle CPU Cores mehr oder weniger gleich verteilt ist.
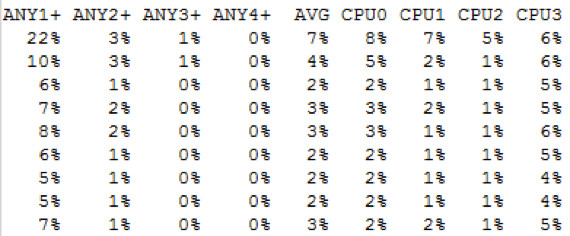
FAS3170b
Wie zu erwarten ist die Last auf dem nicht involvierten Knoten wieder recht gering – es gibt hin und wieder kleine Peaks, die vermutlich von Metadaten Abfragen herrühren dürften.

Die CPU Auslastung im Detail
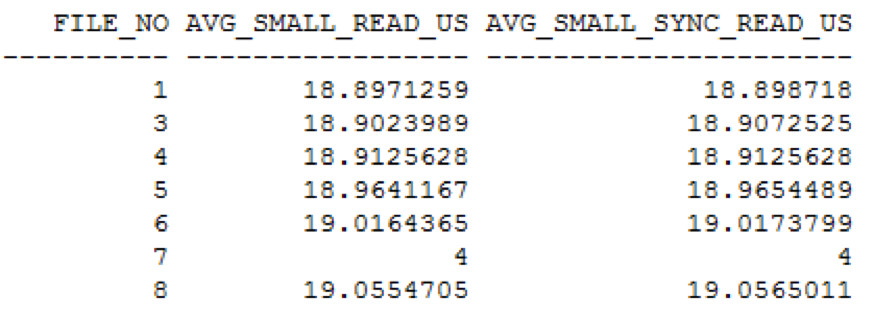
IO Dauer laut v$IOSTAT_FILE
Die Werte sind überraschend niedrig – mit unter 20us (0.02ms) stellt sich die Frage: können die Werte stimmen oder misst Oracle mit pNFS nicht korrekt? Die Anzahl der IOs werden korrekt wiedergegeben, lediglich die I/O Zeiten sind fraglich!
Somit ist das Ergebnis vom I/O Calibrate wichtig, finden wir hier auch sehr gute Daten?
IO Calibrate Ergebnis
I/O Ops/sec = 25547
Und die Antwort ist Ja, absolut. Diese sind zwar immer noch etwas schlechter als bei NFSv3 aber deutlich besser als bei NFSv4.
Performance Test #6: pNFS, Zugriff auf DATA1 auf FAS3170b via ???
Jetzt wird es spannend: Hält pNFS was es verspricht? Die Daten auf der Storage wurden bei laufender Datenbank auf FAS3170b verschoben. Wenn pNFS hält was es verspricht, sollte der Zugriff transparent via FAS3170b erfolgen (zumindest nach kurzer Zeit).
Das Ergebnis ist ernüchternd, es funktioniert nicht, beide Storage Knoten stehen wieder massiv unter Last. Kann es am oranfstab liegen?
-
Versuch #1) donotroute auskommentieren
-
Versuch #2) mehrere Pfade definieren/erlauben
Jeder Versuch zeigt, dass pNFS immer über den gemounteten Pfad zugreift. Entweder gibt es eine spezielle Konfiguration für die oranfstab die wir nicht gefunden haben – die Dokumentation schweigt sich dazu aus – oder es funktioniert einfach noch nicht. Wir haben dazu zwei Service Requests bei Oracle geöffnet.
CPU Auslastung am Datenbank Server
Die CPU Auslastung am Client ist wieder deutlich höher – vergleichbar mit den Tests mit NFSv3.
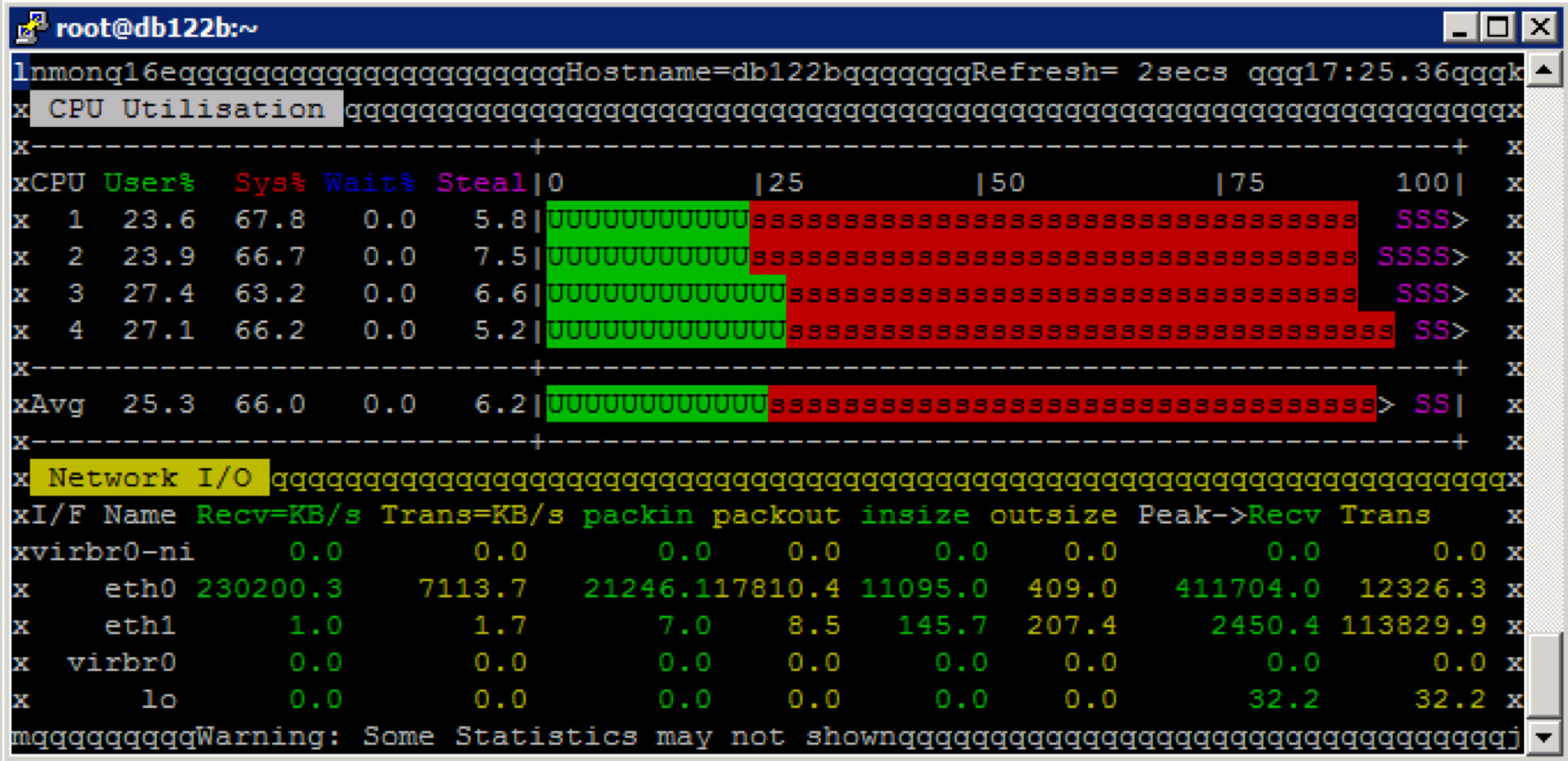
Auslastung auf der Storage
FAS3170a
Die Storage Auslastung ist ähnlich wie bei den anderen NFSv4 Tests – vielleicht ein wenig höher.

Die CPU Auslastung im Detail
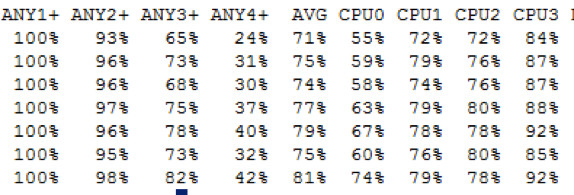
FAS3170b
Auch hier liegt die Last im Bereich des NFSv4 Test, wenn über den falsche Storage Knoten zugegriffen wird.

Die CPU Auslastung im Detail
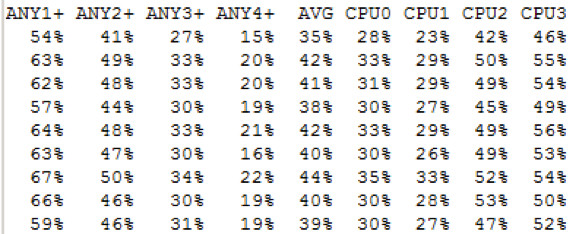
Ergebnis von V$IOSTAT_FILE
Wie zu erwarten liefert uns V$IOSTAT_FILE auch hier keine korrekten Werte.
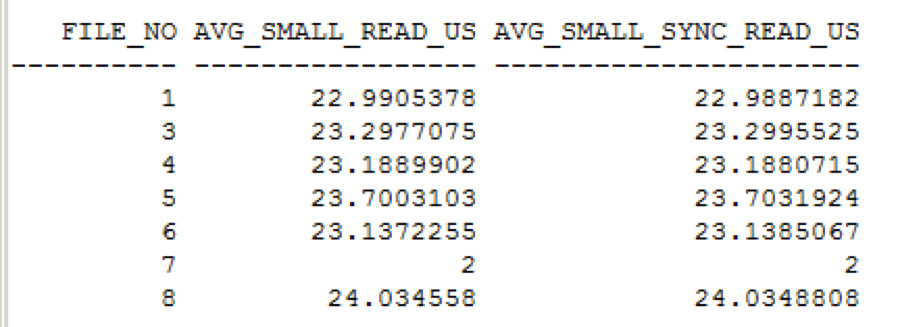
Ergebnis des IO Calibrates
I/O Ops/sec = 24321
Die Werte vom IO Calibrate liegen knapp 10% unter denen der Tests mit NFSv3.
Zusammenfassung
Aktuell funktioniert das Nutzen des optimalen Zugriffspfades mit Oracle pNFS noch nicht und auch die Oracle internen Performance Views liefern im Zusammenhang mit pNFS noch falsche Daten. Interessant ist, dass mit pNFS die Performance im Vergleich mit NFSv3 nur um einige % geringer ausfällt, dafür aber die CPU am Datenbank Server merklich weniger belastet wird.

Auf der Storage Seite ist pNFS offensichtlich merklich aufwändiger und noch nicht so gut optimiert wie es NFSv3 ist – das wird aber in den nächsten Jahren sicher noch optimiert werden. Vielleicht liegt es aktuell auch daran, dass Oracle den „redirect“ auf den anderen Storage Knoten ignoriert.
Soll man schon jetzt auf pNFS umsteigen?
Ein klares Ja für Test/Dev System und ein klares Nein für Produktive Datenbanken. Wie wir schon in den letzten Jahrzehnten gelernt haben, sollte man ein neues Feature bei Oracle frühestens mit der nächsten Release produktiv nutzen (um die Produktion nicht durch die sicher noch vorhandenen BUGs zu gefährden) aber schon jetzt mit dem Sammeln von Erfahrungen beginnen.
Stand: 15. März 2017 - Die gefundenen Probleme wurden bei Oracle gemeldet – wir hoffen auf eine baldige Behebung.
Veröffentlichung dieses Artikels
Dieser Artikel wurde auch auf informatik-aktuell.de veröffentlicht.